


Objective:
As Statistics is being major contribution for research and it overlaps a great deal with machine learning as well as with deep learning applications, we have developed a model in order to find out which statistical concepts applied over particular research papers using topic modeling.
Approach
We have applied LDA (Latent Dirichlet Allocation) a concept of Topic modeling. Topic is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions.
We have scrapped the data from various abstracts from the research papers and then the text was preprocessed by performing the following steps. Tokenization: Split the text into sentences and the sentences into words. Lowercase the words and remove punctuation.Words that have fewer than 3 characters are removed.All stopwords are removed.
Words are lemmatized — words in third person are changed to first person and verbs in past and future tenses are changed into present.
Words are stemmed — words are reduced to their root form.
Then the preprocessed text is converted into features by using TF_IDF algorithm.And these features used to derive the topics using LDA Technique and the derived topics are
• Probability,
• Distributions,
• Inference,
• Design of experiments,
• Sampling theory,
• Regression analysis,
• Multivariate analysis
• Stochastic process
Here is the list of the terms under each topic
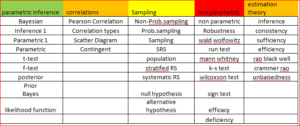
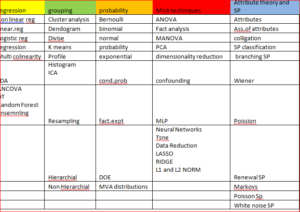
And the topic model is represented using heatmap and dendogram to validate the model. Once the model is validated we developed classification algorithm using navie bayes to classify the future documenting to these topics.
Impact: Whenever we get any new document with this we can easily classify the document in which which statistical concept is applied.
