


PyCaret ( (https://pycaret.org/) is an open-source machine learning library that automates the entire process of training a machine learning model. When using it, you just need to have an idea of the best features you need to train your machine learning model, then you can use PyCaret from model selection to training and testing. Simply put, it automates the entire machine learning process, from choosing which model to select to training and testing your model.
The best feature of PyCaret is that it helps you know which is the best machine learning model that you should use on a particular dataset. It simply shows you the best performing models by ranking the models based on the performance measurement metrics of machine learning models. The best part about this feature is that it does everything with a few lines of code.
first we need to import the required libraries
import pandas as pd import numpy as np from pycaret.classification import * Read data file (This data has the 30 independent variables and one dependent variables which is Grade in this case) student_df = pd.read_csv('student.csv', sep =',') student_df_df.head(10)Removing the slno variable school_df = heart_disease_df.drop(['Slno'], axis=1)
Splinting the data for training and validation sets
hd_data = school_df.sample(frac=0.7, random_state=786).reset_index(drop=True)
hd_data_unseen = school_df.drop(hd_data.index).reset_index(drop=True)
print(‘Data for Modeling: ‘ + str(hd_data.shape))
print(‘Unseen Data For Predictions: ‘ + str(hd_data_unseen.shape))
Data for Modeling: (354, 31) Unseen Data For Predictions: (152, 31) Now let’s set up the model. As this is the problem of classification so I will set up the model for classification. While setting up this model we need to declare the data and the target labels. We also need to declare the features that need to be ignored while training the model. Below is how to set up the PyCaret model for classification:
school_clf = setup(data = hd_data, target = ‘Grade’,
log_experiment = True, session_id=111)
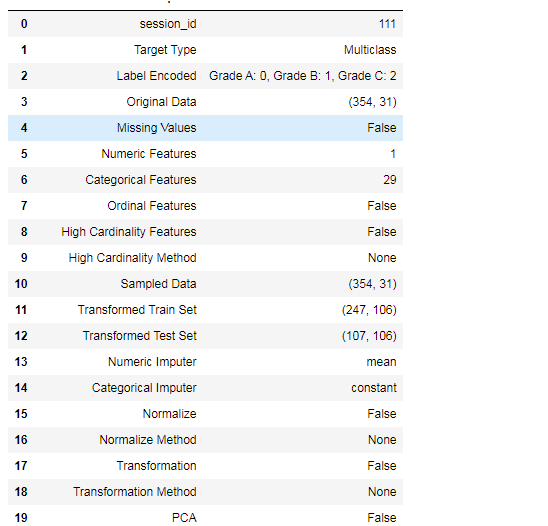
Now I am going to use the most important feature provided by this library which compares models. In machine learning, this is called model selection. If you don’t understand much about model selection, you can use this feature for model selection. Here’s how to compare machine learning models using PyCaret:
school_clf_models =compare_models(n_select = 10)
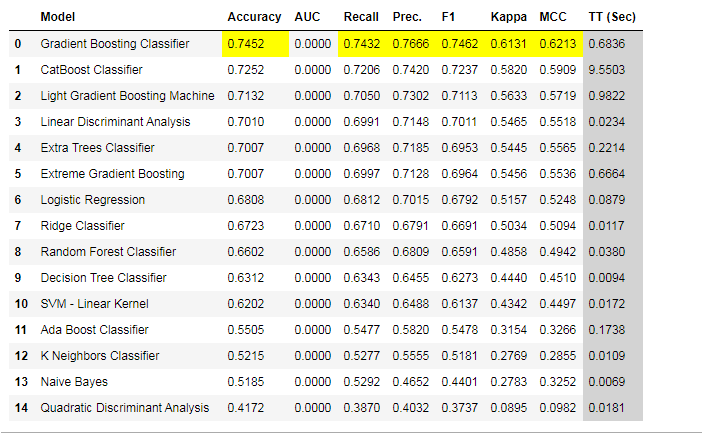
According to the compare models Gradient Boosting classier performing very well on this data
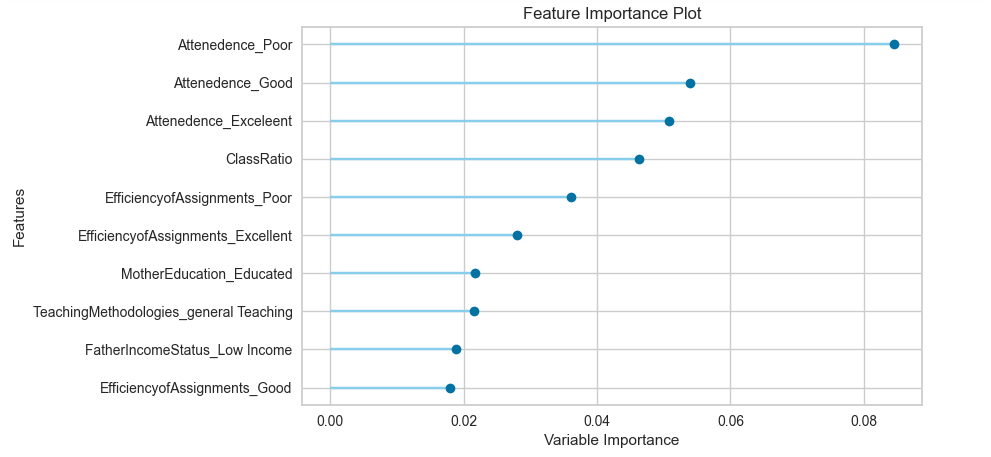
Now we can even find he feature importance
plot_model(school_clf_models[8], plot=’feature’)
Even we can get the global as well as local level interpratabilirty using Shap
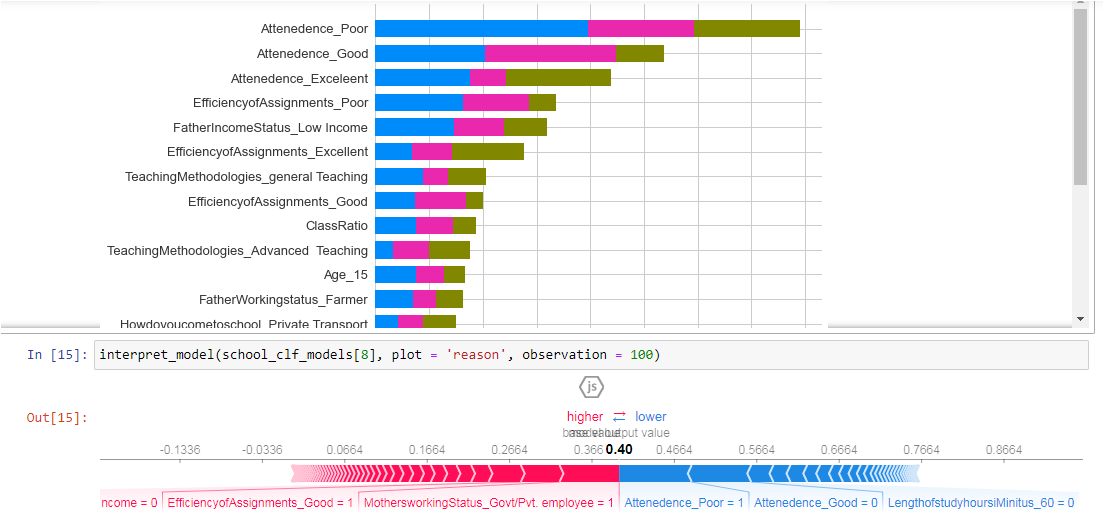
and also performance matrix like Confusion Matrix, Roc Curve –etc
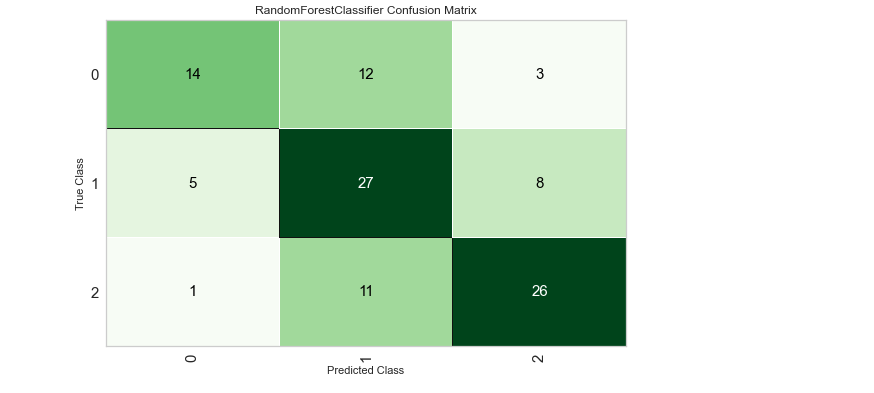
and we save the Model and apply this on the new data
save_model(final_GradientBoostingClassifier,’Final GBC Model 04April2020′)
new_prediction = predict_model(final_GradientBoostingClassifier, data=hd_data_unseen)
new_prediction.head()
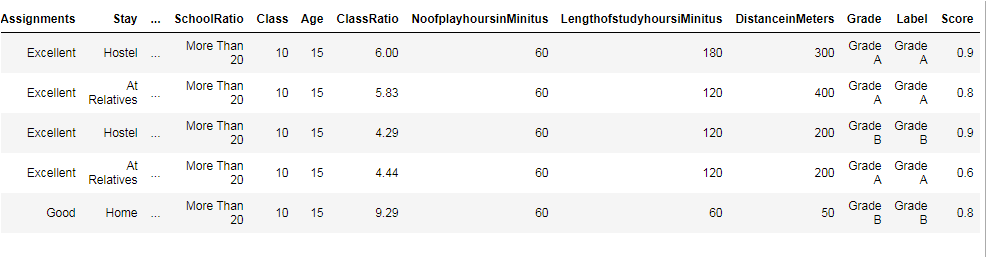
Summary
PyCaret is a great machine learning library to automate the complete process of training a machine learning model as it helps in from model selection to training and testing. You can use it for at least model selection if you don’t like shortcuts while training machine learning models.
