


OBJECTIVE
From the data on various speeches on artificial intelligence and deep learning given by speakers on various platforms, the objective is to understand the different topics covered in those speeches while understanding the similarities among those speeches.
APPROACH
After cleaning the data as a primary step, we move on towards the heart of the analysis i.e., Topic Modelling. This is an approach which takes in multiple text documents in the form of Document Term Matrix as input and groups them into user defined number of topics such that there is homogeneity within the groups and heterogeneity between the groups. The number of topics is decided based on analyst’s judgement keeping in mind that the overlap between frequent words of different groups has to be minimum. We have given the number of topics as 6 as the overlap between the words of these 6 topics is less.
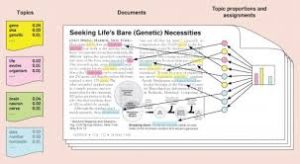
As output we get a list of most frequent words for each topic and Document to topics probabilities for all documents. Based on the top 10 most frequent words in each topic we intuitively decided the topics as follows
- Speech and Audio
- Machine and deep Learning
- Gaming
- Digital and Intelligence
- Network Training
- Building Robots.
Based on the Document to Topic Probability we assign each document to a topic for which the document has the highest probability of belonging to.
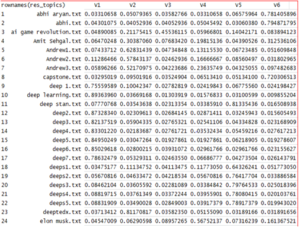
We see that Abhi Aryan spoke mostly about the 6th topic i.e., Building Robots with probability of 0.78. Hence each speech can be classified into these 6 topics.
Heat map is a graphical representation of data where the individual values contained in a matrix are represented as colors. The darkest color represents the highest probability of that particular document belonging to this topic.
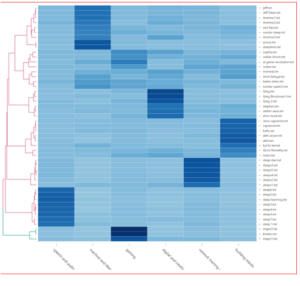
we can see that the speeches of jeff, andrew1, sundar deep ,yosua are speaking mostly about the topic machine and deep learning. We can also see that the speeches of yosua and deeptedx are very similar as distance between them is minute as shown by the dendogram on the left side of the Heat map.
OUTCOME
Using the above analysis we have understood most speeches on AI and deep learning are based on these six topics. Further a classification model, with these topics as different classes of the dependent variable, can be used to predict which one of the topics any new speech is focused on. If a person is interested in speeches in one of the six topics mentioned above then we can recommend a speech which is focused on that topic.
