

In the realm of language models, the emergence of Large Language Models (LLMs) has significantly transformed how we interact with artificial intelligence. These models, while impressive in their ability to provide answers based on extensive training data, face a critical challenge—keeping up with the ever-evolving landscape of information. This blog post hunts through the intricacies of LLMs, explores the challenges associated with their use, and introduces an innovative solution known as Retrieval-Augmented Generation (RAG) to enhance their performance.
The Challenge: Keeping Up with the Pace of Information
LLMs, armed with vast knowledge from their training data, can sometimes fall short when confronted with new and dynamic information. Just like answering a question in a classroom without access to information, LLMs may respond with intriguing yet outdated facts. The absence of a solid source for continuous training poses a significant hurdle, making it imperative to find a solution that adapts to the changing landscape of knowledge.
RAG: Bridging the Gap with Natural Language Processing
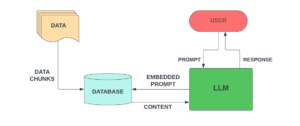
Enter Retrieval-Augmented Generation (RAG), a Natural Language Processing (NLP) based approach designed to address the limitations of traditional LLMs. Unlike conventional methods that rely solely on pre-trained data, RAG introduces a dynamic approach by instructing LLMs to access custom data or documents in real-time.
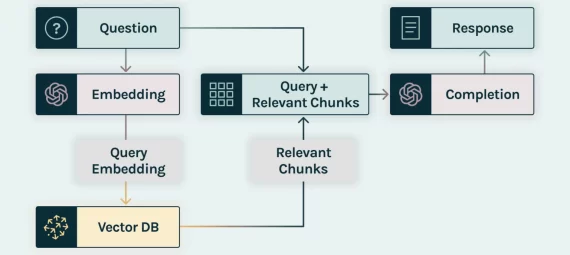
- Creation of Custom Knowledge Base Creation:
- In the technological arena, the solution involves creating a custom knowledge base comprising specific data or documents.
- This custom data serves as a real-time reference for LLMs, ensuring responses are not confined to pre-existing information.
- Breaking Down Information:
- To facilitate learning, RAG breaks down data into manageable sub-topics or information chunks.
- Data chunks are created based on defined lengths, typically a maximum of 1500, to avoid irrelevant responses.
- Vector-Based Representations:
- Sentence transformers, such as paraphrase-MiniLM-L6-v2, are employed to convert these information chunks into vector-based representations.
- These embeddings are stored in a vector database (e.g., FAISS, Chroma DB) for efficient indexing and retrieval.
Training RAG: Retriever and Generator Processes
- Retriever Process:
- Initiated from the user prompt, the retriever process converts the prompt into related embeddings like those in the database.
- Search strategies are employed to find or closely associate relevant embeddings, varying with each vector database. Thus, relevant content is retrieved from the database onto the LLM.
- Generator Process:
- The LLM, armed with instructions, retrieved content, and the user’s prompt, synthesizes these contexts to generate a response.
- The generator’s role is to summarize the information and provide a coherent reply to the user’s query.
Dependencies of RAG:
The success of RAG hinges on two crucial components:
- Enrichment of Prompt Template:
- The relevance and accuracy of generated text are heavily influenced by the enrichment of prompt templates.
- Crafting comprehensive and dynamic prompt templates ensures the generated responses align with user expectations.
- Storage Containers (Databases):
- The databases that index chunked contents play a pivotal role in the effectiveness of RAG.
- Efficient search strategies implemented by these databases are instrumental in retrieving the most relevant and up-to-date information.
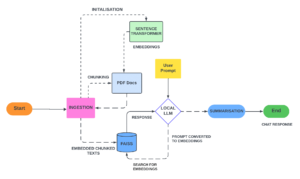
Fig 2: Workflow of RAG Based Chatbot
In conclusion, Retrieval-Augmented Generation represents a ground-breaking approach in the evolution of language models. By combining the strengths of retrieval-based methods and generative models, RAG opens the door to more dynamic and adaptive interactions between users and artificial intelligence.
