


Objective:
Understanding the fairness of the complex machine learning algorithms to apply real time scenario with more and clear interpretability.
Approach:
Without reasonable understanding of how a model or data science pipeline works, real world projects rarely succeed.
This study is about predicting the professor’s salary based on various characteristics like their years of experience, years since phd, discipline, salary, gender, age etc. We have taken a sample of professor’s data and proceeded further as below.
In order to carry out the analysis we have checked scale types, outliers and relationship between the variables , then we applied cross validation on pipeline of machine learning techniques in which Random Forest has given the best accuracy along with important variables i.e rank and discipline as top most important variables.
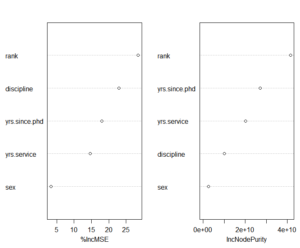
Our main task is to interpret how the random forest has chosen these variables as important.
As this is a complex model (i.e Random forest) and not readily interpretable we applied various interpretability methods at both global and local levels.
Global level interpretation
Initially, to find feature importance at global level we applied permutation based feature importance technique. This method finds the important variables by permuting the features. On applying this method to our data we got rank, yrs.since.phd as top most important variables .
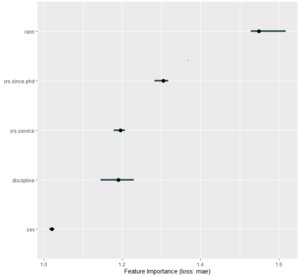
Local level interpretation
In order to find the effect of variables at local regions (i.e ,at respondent level) we have used two methods
- LIME (Local Interpretable Model- Agnostic Explanations)
We first applied LIME technique .This method builds local surrogate models on fake datasets that explain model predictions at local regions using the concepts of proximity and Weights. On applying this method we got the rank , discipline as top most important variables.

- SHAP (Shapley Additive Explanations)
Then we applied one more local interpretable technique ie: Shapley method. This method gives the contribution of each and every feature and also overcomes the limitation of LIME method ie: not considering dependencies between the features. Here we got rank and discipline as top most important variables.

Additionally, we applied Surrogate models and feature interactions at global level to explain the behavior of complex model
Impact:
With these above models we were able to interpret the decision taken by complex model at both global scenario and local (at a respondent level) scenario.
(This article is compiled my teammates Pratima & Rajeswari to enhance their analytical skills at the Lockdown time)
