

NEED
Uplift modeling is a technique used in predictive analytics to estimate the impact of a treatment or intervention on an outcome. It involves predicting the individual treatment effect (ITE) for each individual in the dataset, and then using these predictions to identify the subpopulations of individuals who are most likely to respond positively to the treatment.
- Here are some of the different meta-learner methods used in uplift modeling:
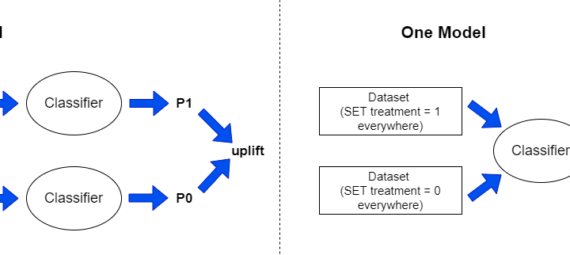
- T-learner: The T-learner is a simple approach to uplift modeling that involves training two separate models for the treatment and control groups. The difference in the predictions from these two models is used to estimate the ITE.
- S-learner: The S-learner is another simple approach to uplift modeling that involves training a single model on the entire dataset, including both the treatment and control groups. The ITE is estimated by subtracting the predicted outcome for an individual in the control group from the predicted outcome for the same individual in the treatment group.
- X-learner: The X-learner is a two-model approach that uses a pre-processing step to estimate the propensity score (i.e., the probability of receiving the treatment). Two models are then trained: one on the treatment group with the propensity score as a covariate, and one on the control group with the propensity score as a covariate. The difference in the predictions from these two models is used to estimate the ITE.
- R-learner: The R-learner is a two-model approach that uses residual-based learning to estimate the ITE. In this approach, one model is trained to predict the outcome for the control group, and another model is trained to predict the residual (i.e., the difference between the observed outcome and the predicted outcome) for the treatment group. The difference between the predicted outcome for an individual in the control group and the predicted residual for the same individual in the treatment group is used to estimate the ITE.
- Causal Forests: Causal forests are a non-parametric approach to uplift modeling that use a tree-based algorithm to estimate the ITE. In this approach, the dataset is split into subpopulations based on the covariates, and a separate model is trained for each subpopulation. The ITE is estimated by comparing the predicted outcome for an individual in the treatment group to the predicted outcome for the same individual in the control group, based on the subpopulation to which they belong.
Each of these meta-learner methods has its own strengths and weaknesses, and the choice of method will depend on the specific characteristics of the dataset and the research question. Ultimately, the goal of uplift modeling is to identify the individuals who are most likely to benefit from the treatment, and the choice of meta-learner will depend on the accuracy, interpretability, and scalability of the method.
