

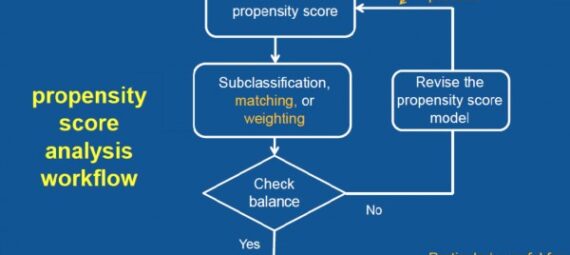
Here are the general steps for implementing propensity score matching to estimate treatment effects in an observational study:
- Define the research question: Start by defining the research question you want to answer. What is the treatment you want to evaluate? What outcome are you interested in measuring?
- Define the study population: Identify the population that will be included in the study and select the variables that will be used to calculate the propensity score. These variables should be known to affect the treatment assignment and the outcome of interest.
- Calculate the propensity score: Use a statistical model (such as logistic regression) to calculate the propensity score for each individual in the study population. The propensity score is the probability of receiving the treatment based on the observed covariates.
- Match treated and untreated individuals: Match treated individuals with untreated individuals who have similar propensity scores. This can be done using nearest neighbor matching, caliper matching, or other matching methods. The goal is to create matched pairs of treated and untreated individuals with similar propensity scores and covariate distributions.
- Assess the balance of covariates: Check the balance of covariates between the treated and untreated groups after matching. The matched groups should have similar covariate distributions to reduce the bias in the treatment effect estimate.
- Estimate the treatment effect: Compare the outcomes between the matched treated and untreated individuals to estimate the treatment effect. This can be done using various methods, such as difference-in-differences, regression models, or weighted analyses.
- Assess sensitivity analysis: Perform sensitivity analysis to evaluate the robustness of the treatment effect estimate. This can include checking the balance of covariates using different matching methods or different propensity score models.
- Interpret the results: Interpret the results and draw conclusions about the treatment effect in the observational study.
These are the general steps for implementing propensity score matching to estimate treatment effects in an observational study. It’s important to note that the specific details of each step may vary depending on the research question, data available, and analytical approach used.
Python code snippet
# Load the necessary libraries and data
import pandas as pd
import numpy as np
from causalml.inference.meta import BaseSlearner
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import NearestNeighbors
df = pd.read_csv(‘treatment_data.csv’)
# Define the treatment and outcome variables
treatment_col = ‘treatment’
outcome_col = ‘outcome’
# Define the covariates to be used in the propensity score model
covariates = [‘age’, ‘gender’, ‘income’]
# Fit a propensity score model using logistic regression
ps_model = LogisticRegression(solver=’lbfgs’, max_iter=10000)
ps_model.fit(df[covariates], df[treatment_col])
# Calculate the propensity scores
ps = ps_model.predict_proba(df[covariates])[:,1]
# Apply nearest neighbor matching using the propensity scores
nn = NearestNeighbors(n_neighbors=1, algorithm=’ball_tree’)
nn.fit(ps.reshape(-1,1))
distances, indices = nn.kneighbors(ps.reshape(-1,1))
# Create matched groups
matched_treatment = df.iloc[indices[:,0]][treatment_col]
matched_outcome = df.iloc[indices[:,0]][outcome_col]
# Estimate the treatment effect using the matched groups
treatment_effect = matched_outcome[matched_treatment==1].mean() – matched_outcome[matched_treatment==0].mean()
print(‘Treatment effect:’, treatment_effect)
R Code Snippet
# Load the necessary libraries and data
library(MatchIt)
df <- read.csv(‘treatment_data.csv’)
# Define the treatment and outcome variables
treatment_col <- ‘treatment’
outcome_col <- ‘outcome’
# Define the covariates to be used in the propensity score model
covariates <- c(‘age’, ‘gender’, ‘income’)
# Fit a propensity score model using logistic regression
ps_model <- glm(treatment_col ~ covariates, data=df, family=binomial())
# Calculate the propensity scores
ps <- ps_model$fitted.values
# Apply nearest neighbor matching using the propensity scores
matched_data <- matchit(treatment_col ~ ps, data=df, method=’nearest’, ratio=1)
# Create matched groups
matched_treatment <- df[matched_data$matches[,1], treatment_col]
matched_outcome <- df[matched_data$matches[,1], outcome_col]
# Estimate the treatment effect using the matched groups
treatment_effect <- mean(matched_outcome[matched_treatment==1]) – mean(matched_outcome[matched_treatment==0])
print(paste(‘Treatment effect:’, treatment_effect))
