Since the time I started off, not only have I grown and evolved as an data scientist, I have also witnessed the data science domain, transform and evolve to what it is now. As we speak, we are, in the midst of this change and evolution; where this leads us to, and how it impacts humanity as a whole, is beyond the realm of anyone’s imagination at this point in time. While the change is a continuum, I, so far, broadly see three distinct phases. Let me try and explain it through the why-how-what framework (by Simon Sinek), in a different context though.
In my opinion, the ‘why’ i.e. ‘why analyse data?’, the core objective has not changed; the goal has always been to find meaning in data so that the derived knowledge can be used to make informed decisions.
As a data scientist, I am closer to the ‘how’ & ‘what’ part of the story i.e. ‘how is data analysed?’& ‘what is the outcome?’ , I speak, not as a far-away observer, but as someone who’s a part of this data science transformation; my point of view will therefore be far more detailed.
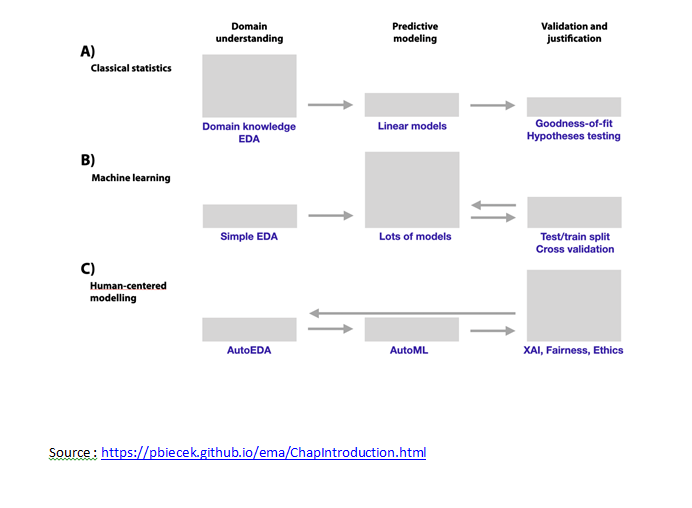
When I started off, in the early 2000s till almost the entire decade, solutions were ‘Inferential/ classical statistical based’. The models are built based on in depth understanding of the domain, the data and a clear view on the utility & application. Domain knowledge was extremely important to identify the variables to be used in relatively simple models that yield predictive scores. These models were evaluated through hypothesis testing. Essentially, the models were simple, inferential statistics based.
By the end of the decade, our ability to store, extract, and analyse data changed drastically. We started to see large, diverse, complex, longitudinal datasets generated from a variety of instruments, sensors and computer based transactions. As the volume, variety, and velocity of data increased, our existing analytical methodologies were stretched to new limits. The deep understanding of domain and application was no longer needed for building and fitting the model, it all became very computationally intensive. This was the era of ‘Machine learning approach & data driven models’; building these modes used a lot of cross validation methods and lot of hyper parameter tuning.
Of late, I see a shift towards ‘Human-centred Approach’; we are seeing automatic machine learning tools which are automating or increasing automation of data exploration and the modelling. Now the focus shifted from building models to validation of the models. The validation from an external as well as an internal perspective, hence importance given to the data literacy (exploration of the data from a business perspective) as well as explanation (Fairness of the algorithm and interpretability of the algorithm). Therefore, in this era there is no dearth of data or computational power or flexible algorithms, the expectation from the model is to lend itself to data literacy, in terms of being intuitive, interpretable and explainable.
I continue to chronicle the transformation as it unfolds; I wish to put down a sequel of this write up a few years down the line 🙂