

LIME (Local Interpretable Model-agnostic Explanations) is a popular method for explaining the predictions of machine learning models, especially black-box models. In this blog post, we will explore the LIME technique, how it works, and its application in healthcare using a use case.
What is LIME?
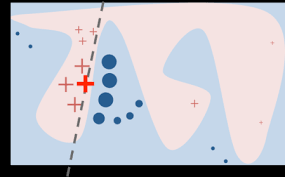
LIME is a model-agnostic method for explaining the predictions of machine learning models. It works by approximating the decision boundary of a complex model with a simpler, interpretable model that can be easily understood by humans. The method is called “local” because it generates an explanation for each individual prediction.
LIME does this by creating a set of perturbations of the original data, and then sampling data points from the perturbed data to build a local, interpretable model. The generated model approximates the decision boundary of the complex model for a specific data point.
How LIME works
The LIME method can be divided into two main steps:
Generating perturbations: This step involves creating perturbations of the original data by adding noise or changing values. The perturbations are created in a way that preserves the distribution of the original data. For instance, if a dataset has numerical and categorical features, the perturbations will have the same distribution of numerical and categorical features.
Building local, interpretable models: In this step, LIME generates a set of weights for each feature in the local, interpretable model, which indicates the importance of each feature for a specific prediction. The weights are generated by fitting a simpler model, such as a linear regression, on the perturbed data. The generated model approximates the decision boundary of the complex model for the specific data point, and the weights are computed based on the contributions of each feature to the prediction.
LIME Use Case: Predicting Diabetes Risk
To demonstrate the LIME technique in healthcare, we will use a dataset of patients at risk of developing diabetes. The dataset contains information such as age, gender, BMI, and blood pressure, as well as a binary label indicating whether the patient developed diabetes within the following five years.
Our goal is to build a model that can predict whether a patient is at risk of developing diabetes based on their medical history. We will use a random forest model for this task, as it is a common and effective method for binary classification tasks.
After training the random forest model, we can use LIME to explain the model’s predictions for a specific patient. For example, let’s consider a patient who is 45 years old, female, with a BMI of 32 and a blood pressure of 140/90. The random forest model predicts that this patient is at high risk of developing diabetes.
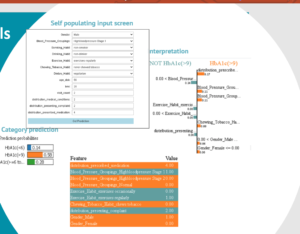
Using LIME, we can generate a set of perturbed instances around this patient by randomly sampling values for each feature within a small neighborhood of the original value. We can then train a local, interpretable model (in this case, a linear regression) on this perturbed data to approximate the decision boundary of the random forest model around this patient.
The weights generated by the local model can be visualized using a bar chart or heatmap to show the contribution of each input feature to the model’s prediction. In this case, the LIME visualization shows that BMI and age are the most important factors for predicting diabetes risk for this patient.
Conclusion
LIME is a powerful method for explaining the predictions of machine learning models, especially black-box models. By generating perturbed data and building local, interpretable models, LIME provides a way to understand the contribution of each feature to a specific prediction. In healthcare, LIME can be used to understand the factors that contribute to the risk of developing certain diseases, allowing healthcare professionals to provide personalized treatments and interventions to
