

OBJECTIVE:
Now-a-days, usage of social media has increased widely. By using social media like Twitter, YouTube, IMDB etc. users can post their reviews about movies. The economists, investors and predictive analysts are very interested to predict the success of their movies. For predicting budget invested, sequel, genre, ratings, views, likes, dislikes etc. This problem is related to the prediction of the gross of the Hollywood movies released in the years 2014 and 2015.
Broadly the objectives of the problem are:
- What are the key parameters that we can use to predict the GROSS income of a movie?
- Which algorithm can best predict the GROSS of a new movie, given the data for all other variables?
Here in this dataset, Year, Ratings, Budget, Screens, Sequels, Views, Likes, Dislikes, Comments and Aggregate Followers are independent variables whereas, gross is a dependent variable.
APPROACH:
Data cleaning and pre-processing is carried out in the following steps:
- Year, Genre and Sequel are read as Integer variables but, they are actually nominal in nature. Hence, we have converted these into factor variables
- Missing values in AF, Screens and Budget are imputed with their respective mean values as these are all continuous variables
- Changing all the imputed variables to numericData Understanding
- Understanding data using descriptive statistics
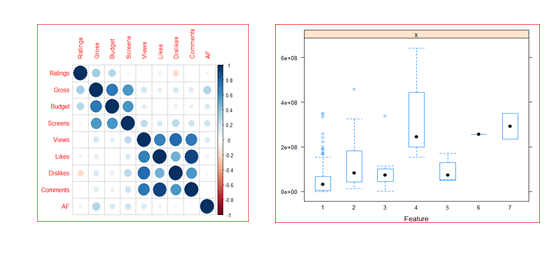
- Visual Understanding of relationships among variables in data using pair plot, correlation plot and feature plot(dependent Vs. independent)
- Data Modelling and Evaluation:
- Cross validation: We split the data into train and test in proportion of 70 and 30 respectively.
- We considered 10 folds for validating the Train data set and run the below techniques in pipeline to choose the best algorithm. As this is a Regression problem, we have considered Linear Regression, GLM, Decision Tree, k-NN, SVM and Random Forest as part of the pipeline.
- Linear Regression explains 61.4% of the total variance
- Generalized Linear Model explains 61.37% of the total variance
- Decision trees explains 67% of the total variance
- K-nearest neighbors explains 56.92% of the total variance
- support vector machines explains 39.25% of the total variance
- random forest explains 65.16% of the total variance
-
- comparing algorithms:
We can see that Random Forest gives the best accuracy followed by Generalized Linear model.
- Finding the Key variables using Random Forest:
Using variable importance given by random forest, we see that Screens, Ratings, Budget, Sequel and Genre are the variables which have more importance than other variables in predicting Gross. Using these key variables we fitted a Generalized Linear Regression model (as opposed to random forest because GLM is easily interpretable unlike random forest)and obtained an accuracy of 67.4% (trained data) and 73.83% (test data).
OUTCOME:
Objective 1: The identified key variables are Budget, Ratings, Genre, Sequel and Screens which we use to predict the GROSS.
Objective 2: From the pipe line of techniques we have shortlisted Multiple Linear Regression as the best model based on R-square value. We also identified the key variables using Random Forest.
R-square for train data is: – 67.38 ̴ 67%
R-square for test data is: – 73.84 ̴ 74%
Since, the accuracy of train and test data is more or less similar. Hence, the model is a Generalized model, so we can use this model to predict the future data.
( This Blog is complied by James & His team for their MSc Project)
