


Need: When you identified missing data has a pattern with other variables (Missing at Random MAR) imputing the missing values with single value (Mean/Mode) imputation does not make any sense. As missing data has some kind relation with other variables, we need to use some of the predictive based imputation methods in this circumstance.
Approach: MICE or Multiple Imputation by Chained Equation
How it will work
Multiple imputation by chained equations (MICE) has emerged in the statistical literature as one principled method of addressing missing data. Creating multiple imputations, as opposed to single imputations, accounts for the statistical uncertainty in the imputations. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g., continuous or binary) as well as complexities such as bounds.
The chained equation process can be broken down into the following general steps:
Step 1: A simple imputation, such as imputing the mean, is performed for every missing value in the dataset. These mean imputations can be thought of as “place holders.”
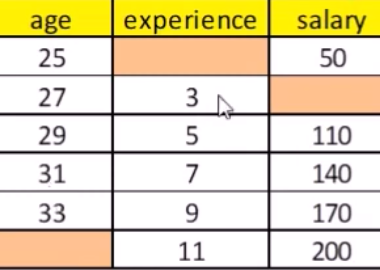
Step 2: Start Step 2 with the variable with the fewest number of missing values. The “place holder” mean imputations for one variable (“var”) are set back to missing.
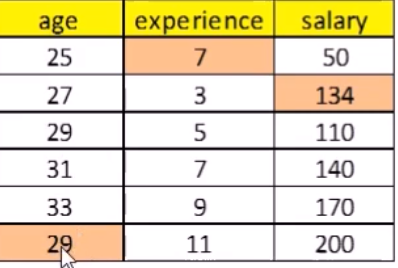
 Step 3: “var” is the dependent variable in a regression model and all the other variables are independent variables in the regression model.
Step 3: “var” is the dependent variable in a regression model and all the other variables are independent variables in the regression model.
Step 4: The missing values for “var” are then replaced with predictions (imputations) from the regression model. When “var” is subsequently used as an independent variable in the regression models for other variables, both the observed and these imputed values will be used.


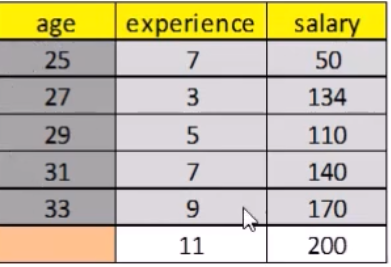
Step 5: Moving on to the next variable with the next fewest missing values, steps 2–4 are then repeated for each variable that has missing data. The cycling through each of the variables constitutes one iteration or “cycle.” At the end of one cycle all of the missing values have been replaced with predictions from regressions that reflect the relationships observed in the data.
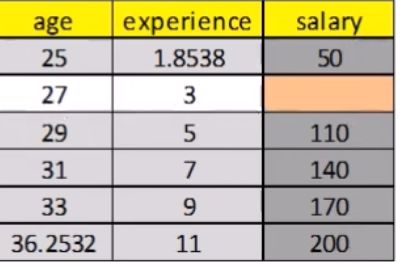
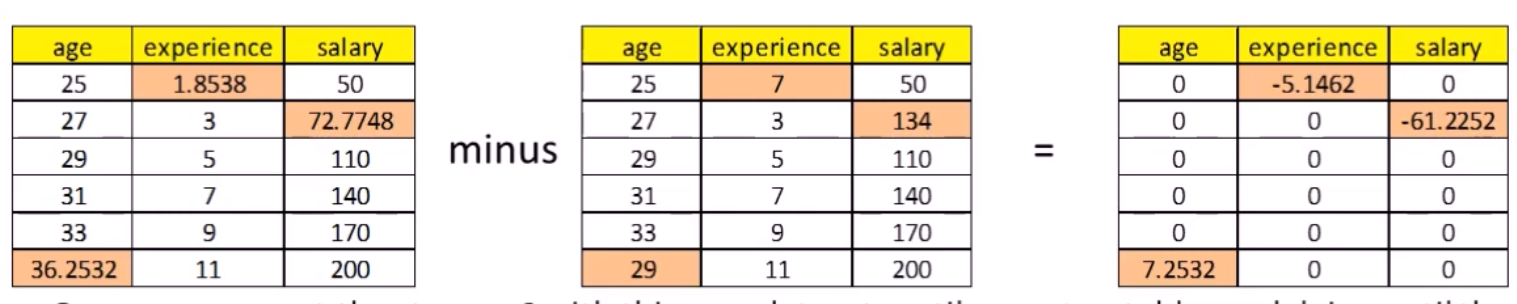 Step 6: Steps 2 through 4 are repeated for a number of cycles, with the imputations being updated at each cycle. The idea is that by the end of the cycles the distribution of the parameters governing the imputations (e.g., the coefficients in the regression models) should have converged in the sense of becoming stable.
Step 6: Steps 2 through 4 are repeated for a number of cycles, with the imputations being updated at each cycle. The idea is that by the end of the cycles the distribution of the parameters governing the imputations (e.g., the coefficients in the regression models) should have converged in the sense of becoming stable.
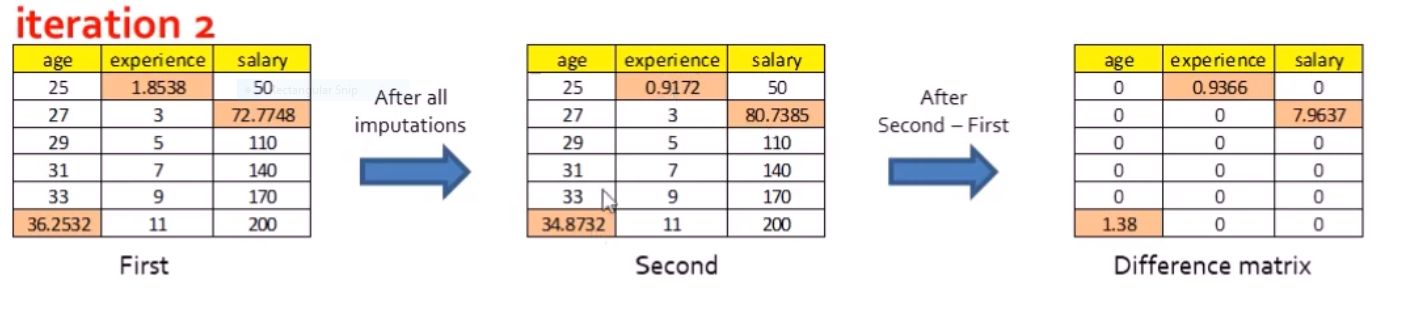
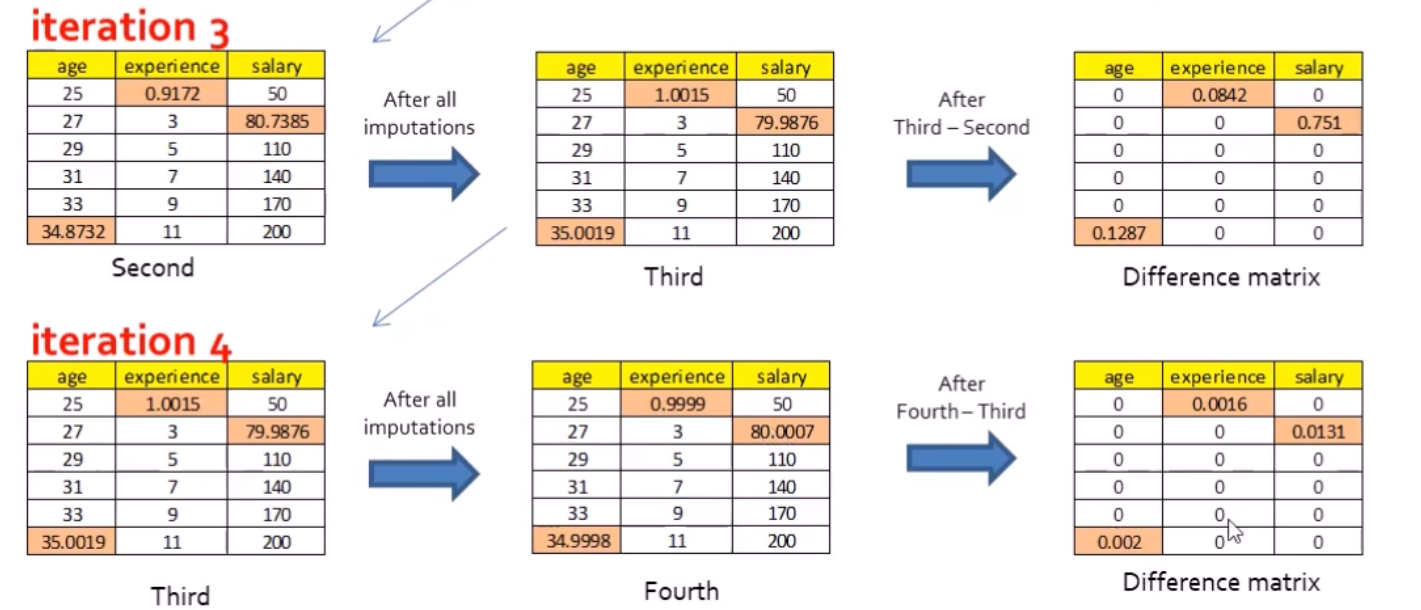
This entire process of iterating through the three variables
would be repeated until some measure of convergence, where the imputations are stable; the observed data and the final set of imputed values would then constitute one “complete” data set.
We then repeat this whole process multiple times in order to get multiple imputations.
Source:
https://www.youtube.com/watch?v=WPiYOS3qK70
https://github.com/drstatsvenu/Missing-pattern/blob/main/Mice%20in%20python.ipynb
